---
title: "Discrete Choice Experiment"
format:
html:
code-fold: true # Enables dropdown for code
code-tools: true # (Optional) Adds buttons like "Show Code"
code-summary: "Show code" # (Optional) Custom label for dropdown
toc: true
toc-location: left
page-layout: full
editor: visual
bibliography: references.bib
---
# Stated Preference : DCE
Discrete Choice Experiments (DCEs) present respondents with several choice scenarios, each containing multiple alternatives described by various attributes and their levels. Respondents choose their preferred alternative in each scenario. R packages facilitate the design of DCEs (e.g., using orthogonal main-effect designs) and the analysis of choice data using models like conditional and binary logit.
For our example we will be using this book
[Environmental Valuation with Discrete Choice Experiments in R](https://library.oapen.org/bitstream/handle/20.500.12657/104194/1/9783031893384.pdf) [@mariel2025]

These are the libraries you need to run the code below:
```{r echo=TRUE, message=FALSE, warning=FALSE, results='hide'}
# Note if you don't have packages install.packages("put library name in here")
#install.packages("Rfast")
#install.packages("spdesign")
#install.packages("tidyr")
#install.packages("tibble")
library(Rfast)
library(spdesign)
library(ggplot2)
library(tidyr)
library(tibble)
```
We will use the example the above book uses through out the chapters.
## Attribute & Levels
+------------------------------------+---------------+--------+
| Attributes | Labels | Levels |
+====================================+===============+========+
| Size of Wind Farm (discrete) | Small Farms | 0 |
+------------------------------------+---------------+--------+
| ***Note reference is LargeFarm*** | | 1 |
+------------------------------------+---------------+--------+
| | MediumFarms | 0 |
+------------------------------------+---------------+--------+
| | | 1 |
+------------------------------------+---------------+--------+
| Max. Height Turbine (discrete) | Low Height | 0 |
+------------------------------------+---------------+--------+
| ***Note reference is HighHeight*** | | 1 |
+------------------------------------+---------------+--------+
| | Medium Height | 0 |
+------------------------------------+---------------+--------+
| | | 1 |
+------------------------------------+---------------+--------+
| Reduction in Red Kite (continous) | Red Kite | 5 |
+------------------------------------+---------------+--------+
| | | 7.5 |
+------------------------------------+---------------+--------+
| | | 10 |
+------------------------------------+---------------+--------+
| | | 12.5 |
+------------------------------------+---------------+--------+
| | | 15 |
+------------------------------------+---------------+--------+
| Distance to residents (continous) | MinDistance | 750 |
+------------------------------------+---------------+--------+
| | | 1000 |
+------------------------------------+---------------+--------+
| | | 1250 |
+------------------------------------+---------------+--------+
| | | 1500 |
+------------------------------------+---------------+--------+
| | | 1750 |
+------------------------------------+---------------+--------+
| MonthlyCost | Cost | 0 |
| | | |
| (Continous) | | |
+------------------------------------+---------------+--------+
| | | 1 |
+------------------------------------+---------------+--------+
| | | 2 |
+------------------------------------+---------------+--------+
| | | 3 |
+------------------------------------+---------------+--------+
| | | 4 |
+------------------------------------+---------------+--------+
| | | ..... |
+------------------------------------+---------------+--------+
| | | .... |
+------------------------------------+---------------+--------+
| | | 10 |
+------------------------------------+---------------+--------+
## Choice Set
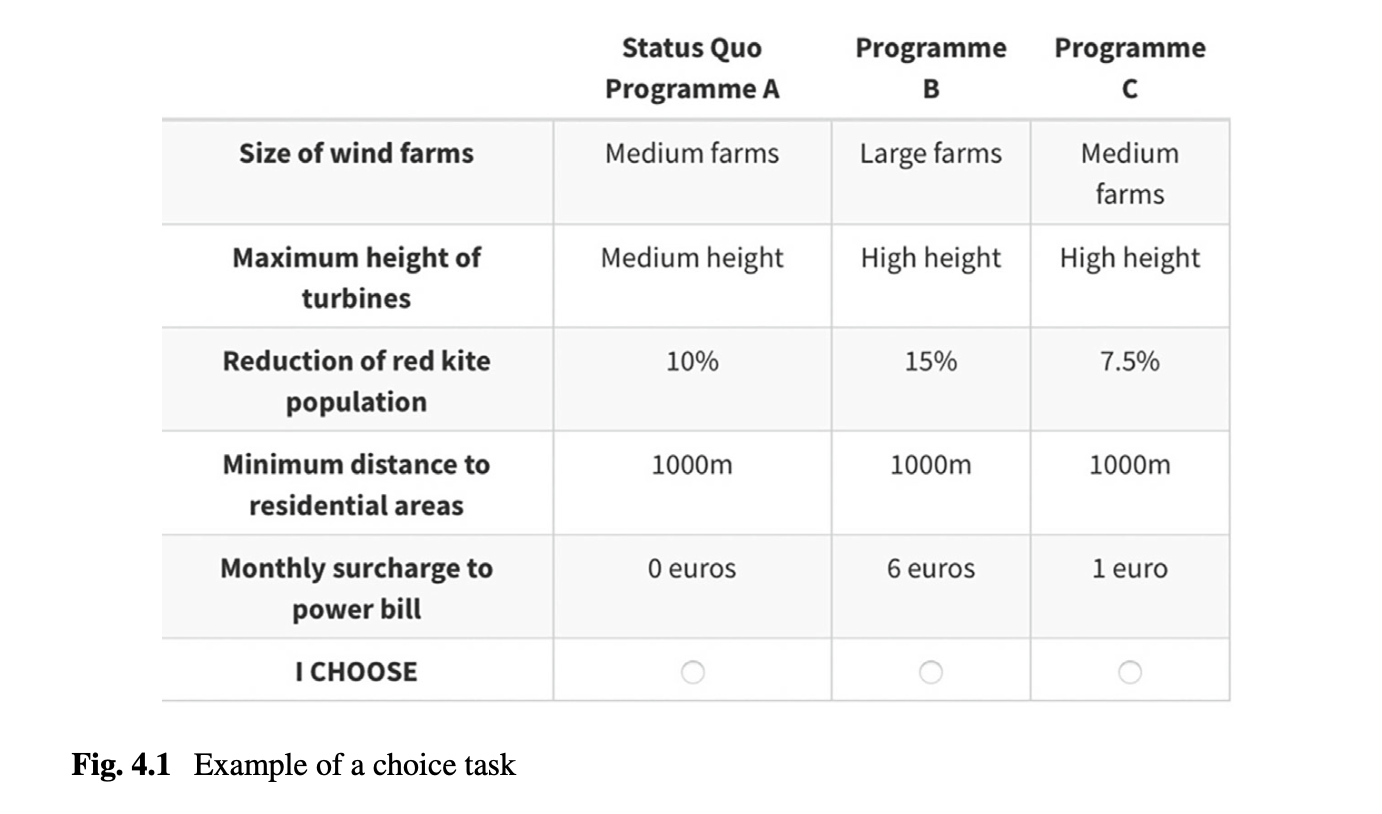
Lets first consider this example
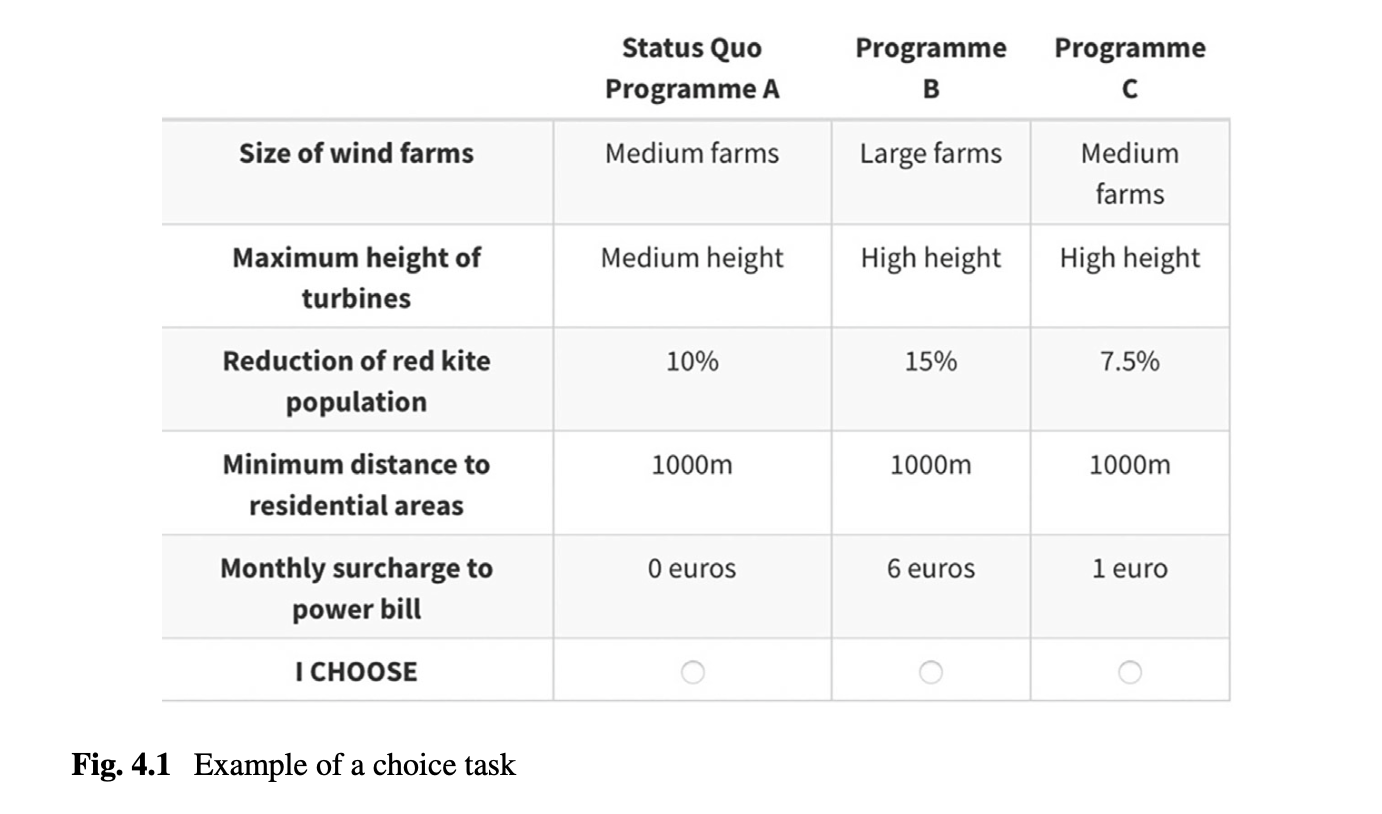
This choice card has 3 alternatives and thus 3 different utility functions you are estimating:
- The status quo or the opting out and keeping things the way they are. The utility function would look something like this:
$$
\begin{aligned}
U_{n1t} =\; & \beta_{mf} \, Med.Farms_{n1t} + \beta_{sf} \, SmallFarms_{n1t} \\& + \beta_{mh} \, Med.Height_{n1t} + \beta_{lh}
\, LowHeight_{n1t} \\& + \beta_{rk} \, redKite_{n|t} + \beta_{md} \, MinDistance_{n1t} \\& + \beta_{cost} \, Cost_{n1t} + \epsilon_{n1t}
\end{aligned}
$$
- Program B will be alternative 2 and thus is indexed by 2
$$
\begin{aligned}
U_{n2t}= \beta_{mf}Med.Farms_{n2t}+\beta_{sf}SmallFarms_{n2t} \\
+\beta_{mh}Med.Height_{n2t}+\beta_{lh}LowHeight_{n2t} \\
+\beta_{rk}redKite_{n2t}+\beta_{md}MinDistance_{n2t} \\
\beta_{cost}Cost_{n2t}+ \epsilon_{n2t} \\
\end{aligned}
$$
- Program C will be alternative 3 and thus is indexed by 3
$$
\begin{aligned}
U_{n3t}= \beta_{mf}Med.Farms_{n3t}+\beta_{sf}SmallFarms_{n3t} \\
+\beta_{mh}Med.Height_{n3t}+\beta_{lh}LowHeight_{n3t} \\
+\beta_{rk}redKite_{n3t}+\beta_{md}MinDistance_{n3t} \\
\beta_{cost}Cost_{n3t}+ \epsilon_{n3t} \\
\end{aligned}
$$
## Experiential Design
We will now look at a full factorial design for the entire choice set and all the levels. Given the choices above the amount of possible combinations balloons to 5mil+ observations!
```{r}
# Create the full factorial using a named list of attributes and levels in the wide format
full_fact <- full_factorial( list( alt1_sq = 1,
alt1_farm = 0,
alt1_height = 0,
alt1_redkite = 0,
alt1_distance = 0,
alt1_cost = 0,
alt2_sq = 0,
alt2_farm = c(1, 2, 3),
alt2_height = c(1, 2, 3),
alt2_redkite = c(-5, -2.5, 0, 2.5, 5), alt2_distance = c(0, 0.25, 0.5, 0.75, 1), alt2_cost = 1:10,
alt3_sq = 0,
alt3_farm = c(1, 2, 3),
alt3_height = c(1, 2, 3),
alt3_redkite = c(-5, -2.5, 0, 2.5, 5), alt3_distance = c(0, 0.25, 0.5, 0.75, 1), alt3_cost = 1:10
) )
# Show the first six rows and 8th to 12th columns of the design matrix
full_fact[1:6, c(1, 8:12)]
```
As the number of attributes, levels, and alternatives increases, full factorial designs become less practical for several reasons:
1. **Duplicate alternatives**: Some choice tasks may repeat the same alternative, which doesn't help us learn anything new about preferences.
2. **Dominated alternatives**: Some options in a choice task might be clearly worse (or better) than others in every way. These don't help reveal trade-offs because people will always pick the best one, making the data less useful.
3. **Lack of control**: The full factorial includes all possible combinations, even unrealistic ones. For example, we might want to prevent small wind farms from showing up with the highest red kite impact.
### Logical Operators
Lets say we want to put restriction by putting logical restrictions. For example, the tall windmills cannot be placed too close to residential areas (this could already be a law and thus is a more accurate reflection of reality).
```{r}
candidate_set <- full_fact[!((full_fact$alt2_height == 1 & full_fact$alt2_distance < 0.75) | (full_fact$alt3_height == 1 & full_fact$alt3_distance < 0.75)), ]
candidate_set[1:6, c(1, 8:12)]
```
This reduces the number of observations to 3.2million+ but does not make our choice set reasonable for population sampling. There for we move onto the next approach D-efficient
### D-efficient Design
In statistics, we often try to reduce standard errors to improve the precision of our estimates. The same idea applies in Discrete Choice Experiments (DCEs). We want to design choice tasks that give us the most precise information.
Think of it this way:
- When fitting a model, we already have the data and estimate the parameters that best explain it.
- When designing a DCE, we do the reverse: we assume values for the parameters (called *priors*) and then search for the combination of attributes and levels that will give us the most information --- that is, the lowest standard errors or lowest D-error.
### Utility Function
For our example we need to design a utility function to estimate the best set of potential choice cards. The utility function was written out within choice set section. So here we are going to use the library `spdesign` to write out each alternative.
```{r}
utility <- list(
alt1 = "b_sq[0] * sq[1]",
alt2 = "b_farm_dummy[c(0.25, 0.5)] * farm[c(1, 2, 3)] +
b_height_dummy[c(0.25, 0.5)] * height[c(1, 2, 3)] + b_redkite[-0.05] * redkite[c(-5, -2.5, 0, 2.5, 5)] + b_distance[0.5] * distance[c(0, 0.25, 0.5, 0.75, 1)] + b_cost[-0.05] * cost[seq(1, 10)]",
alt3 = "b_farm_dummy * farm + b_height_dummy * height +
b_redkite * redkite + b_distance * distance + b_cost * cost"
)
```
### Generating Design
In library **spdesign** `generate_design`is a function that generates efficient experimental designs. The function takes a set of indirect utility functions and generates efficient experimental designs assuming that people are maximizing utility.
Here are the arguments needed for our example:
| | |
|-----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `utility` | A named list of utility functions. See the examples and the vignette for examples of how to define these correctly for different types of experimental designs. |
| `rows` | An integer giving the number of rows in the final design |
| `model` | A character string indicating the model to optimize the design for. Currently the only model programmed is the 'mnl' model and this is also set as the default. |
| `efficiency_criteria` | A character string giving the efficiency criteria to optimize for. One of 'a-error', 'c-error', 'd-error' or 's-error'. No default is set and argument must be specified. Optimizing for multiple criteria is not yet implemented and will result in an error. |
| `algorithm` | A character string giving the optimization algorithm to use. No default is set and the argument must be specified to be one of 'rsc', 'federov' or 'random'. |
```{r}
# Generate design ----
design <- generate_design(utility, rows = 100,
model = "mnl", efficiency_criteria = "d-error", algorithm = "rsc")
```
```{r}
summary(design)
```
### Correlation
Next step check correlation
```{r}
# Correlation matrix
cor(design)
```
### Attribute Balance
```{r}
# Print only the first three list elements
level_balance(design)[1:3]
```
First, we can see that the constant for the status quo alternative appears in all 100 rows of the design. Next, the medium and small wind farm sizes each occur 33 times, meaning the large size appears 34 times. This suggests the design is nearly balanced across attribute levels.
### Dominated Strategy Check
**Dominant or dominated** alternatives should be avoided because they don't provide useful information about trade-offs and can bias your results.
To check for this, we can look at the choice probabilities for each alternative. If one option has a probability close to 1, it likely dominates the others. If it's close to 0, it's probably dominated.
The `spdesign` package includes a `probabilities()` function that calculates these values based on your design and priors. It shows the probability of choosing each alternative in every choice task. Each row of the output adds up to 1.
```{r}
# Check the utility balance by inspecting the probabilities. We use head() to avoid printing all 100 rows in the book.
probabilities(design) |>
head()
```
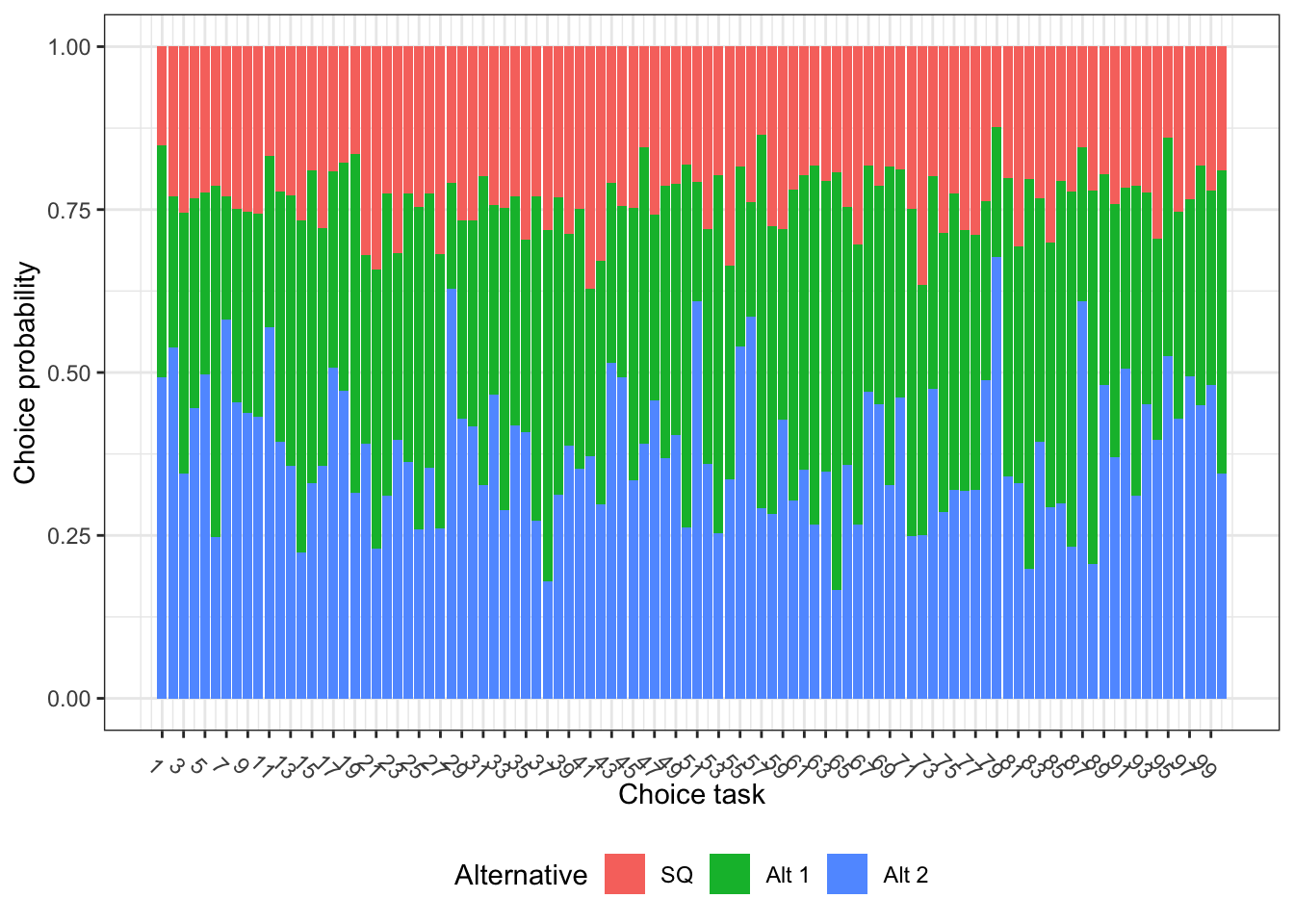
To help spot any problematic choice tasks, we can create a simple plot. In this case, the plot shows no signs of [dominating or dominated]{.underline} alternatives which would appear as very large or very small segments of a single color.
The [status quo option]{.underline} (shown in red) has a low probability of being chosen, but it's not too low to be a problem. What's considered "too low" depends on the context. For example, in [labelled experiments]{.underline}, some options are naturally chosen less often, especially if they represent less common situations.
If the status quo is chosen too often or too rarely compared to your expectations, you should adjust its prior value:
- Increase the prior if you expect more people to choose the status quo.
- Decrease it if you expect fewer to choose it.
This step highlights why it's important to check your design and make sure the priors match what you expect from real-world behavior.
```{r}
# Create a plot to show the choice shares across the design
probabilities(design) |>
as_tibble() |>
rowid_to_column() |>
pivot_longer(-rowid, names_to = "alt", values_to = "prob") |> ggplot(aes(x = rowid, y = prob, fill = alt)) + geom_bar(position = "fill", stat = "identity") +
labs(x = "Choice task", y = "Choice probability", fill = "Alternative") + scale_x_continuous(breaks = seq(1, 100, by = 2)) + scale_fill_discrete(label = c("SQ", "Alt 1", "Alt 2")) +
theme_bw() +
theme(
legend.position = "bottom", axis.text.x = element_text(angle = 315)
)
```
### Utility Balance
So next on the list would be check utility balance of each choice task in our design.
```{r}
utility_balance <- function(x) {
#Ensure that it is a matrix (and not a data.frame()/tibble())
x <- as.matrix(x)
# Find number of non-zero alternatives where 0 or NA can be non-available
n_alts <- apply(x, 1, function(y) sum(y > 0, na.rm = TRUE))
# Calculate for each alternative
x <- x / (1 / n_alts)
#Replace all zeroes with 1 to enable taking the product
index_zero <- x == 0
x[index_zero] = 1
# Take the product. This line requires the Rfast package.
x <- Rfast::rowprods(x)
return(x)
}
# Use the function for utility balance on the choice probabilities
utility_balance(probabilities(design)) |>
head()
```
The function returns the utility balance for each choice task. The average utility balance across the design is 0.8478. For efficient designs, values typically fall between 70% and 90% indicates a good balance, not too equal (which gives little information) and not too skewed to have dominant alternatives.
### Block Design
The design created in this includes 100 choice tasks which is far too many for a single respondent to handle effectively. To address this, we present two common solutions, starting with the most widely used: **blocking**.
Blocking involves dividing the full design into smaller subsets, or *blocks*, so that each respondent is only shown the tasks from one block. For example, if pre-testing shows that respondents can comfortably complete 10 tasks, then a 100-task design would be split into 10 blocks of 10 tasks each.
Each choice task still needs to be answered by at least one respondent, so blocking increases the number of participants required. In this case, you'd need at least 10 respondents (one per block), instead of just one respondent completing all 100 tasks. In general, larger designs with blocking demand more respondents to ensure all tasks are adequately covered.
When using a blocked design, each respondent is randomly assigned to a block, and the order of choice tasks within that block is also randomized. Be sure to record the specific choice tasks shown to each respondent so you can accurately reconstruct their responses later.
The blocking column in your design must be orthogonal, meaning it should not be correlated with the other attributes. The `block()` function from the `spdesign` package creates a blocking column that minimizes mean squared correlation. However, it does not preserve attribute level balance within each block.
If your overall design is balanced, blocking won't change that. But keep in mind that in a blocked design, some respondents may never see certain attribute levels, which could affect how realistic the choice tasks feel. Also, depending on the complexity of your design, generating the blocking column may take some time.
```{r}
# Add a blocking variable to the design with 10 blocks.
design <- block(design, 10)
```
```{r}
design$blocks_correlation
```
Here, we see that the blocking column is practically uncorrelated with the rest of the design.